

The AI product development lifecycle is the structured, repeatable process teams use to take an AI product from an initial problem statement through data work, model building, deployment, and ongoing improvement.
That sentence is the whole article in miniature. But knowing the stages exist and actually knowing how to run them are two very different things – and most PMs find that out the hard way, usually around week six of a project that “should have taken a month”.
It’s not a one-time checklist — it’s closer to a loop than a line.
Here’s the distinction that trips people up: adding one AI feature to an existing product is a project. The AI product development roadmap is bigger than that. It’s the whole operating model for how your team identifies problems AI can actually solve, builds toward them responsibly, and keeps the resulting product working well after launch.
This guide walks through what the lifecycle actually is, why it’s worth following even under pressure to move fast, and what each of the seven stages involves — from defining the right problem to keeping a model healthy long after launch. It also covers how this lifecycle differs from a traditional software build and where teams tend to get stuck along the way.
Key takeaways
-
- The AI product development lifecycle has seven stages — problem definition, data discovery, approach selection, prototyping, MVP development, deployment, and ongoing monitoring — and it works more like a loop than a straight line, with later stages often sending you back to revisit earlier ones.
- Skipping Stage 1 is the single biggest reason AI projects fail. A real problem statement needs a measurable goal attached — “Let’s use AI for this” is a hunch, not a plan. a plan.
- Data discovery and preparation are usually the most time-consuming stage, and almost every team underestimates how much they shape everything that comes after.
- The right technical approach — API, RAG, or fine-tuned model — should match what the problem actually needs, not which option looks the most technically impressive.
- Unlike traditional software, an AI product never really “finishes” at launch. Its outcomes are probabilistic rather than fixed, and ongoing monitoring is part of the product, not a maintenance afterthought.
- Following this lifecycle isn’t about getting every stage perfect. It’s about building a structure that makes problems visible early enough to fix, which is what separates teams that recover from ones that don’t.
- The AI product development lifecycle has seven stages — problem definition, data discovery, approach selection, prototyping, MVP development, deployment, and ongoing monitoring — and it works more like a loop than a straight line, with later stages often sending you back to revisit earlier ones.
Why the AI Product Development Lifecycle Matters
The honest pitch for following a formal lifecycle is simple: it catches expensive mistakes early, keeps AI work tied to a real business outcome, and ensures the product keeps getting better after launch rather than slowly going stale.
The benefits of the AI product development lifecycle are given below
-
- It reduces risk and uncertainty. Finding out your dataset is too thin, or your model just isn’t accurate enough, is a lot cheaper in week three than in month six. The lifecycle is basically a series of checkpoints designed to surface bad news early, when it’s still cheap.
- It keeps technical work tied to business goals. Without a defined process, it’s easy to end up with a model that’s genuinely impressive on a whiteboard and completely irrelevant to what the business actually needs. The lifecycle forces a “why are we building this” conversation before anyone starts training anything.
This is the same trap behind why digital products fail to find product-market fit — technically sound work that nobody actually needs.
- It makes stakeholder conversations easier. When someone in leadership asks why data prep is eating six weeks of the timeline, having a named stage for that work — and a track record of why it matters — turns an awkward conversation into a normal one.
- It builds in scalability from day one. Skip model versioning, data governance, or basic monitoring early on, and you’ll pay for it later, usually right when you’re trying to scale and have the least time to fix it.
- It supports continuous improvement. Unlike most software, an AI product is supposed to keep getting smarter after it ships. That’s not a maintenance afterthought — it’s the actual point of building something that learns.
- It reduces risk and uncertainty. Finding out your dataset is too thin, or your model just isn’t accurate enough, is a lot cheaper in week three than in month six. The lifecycle is basically a series of checkpoints designed to surface bad news early, when it’s still cheap.
The 7 Stages of the AI Product Development Lifecycle
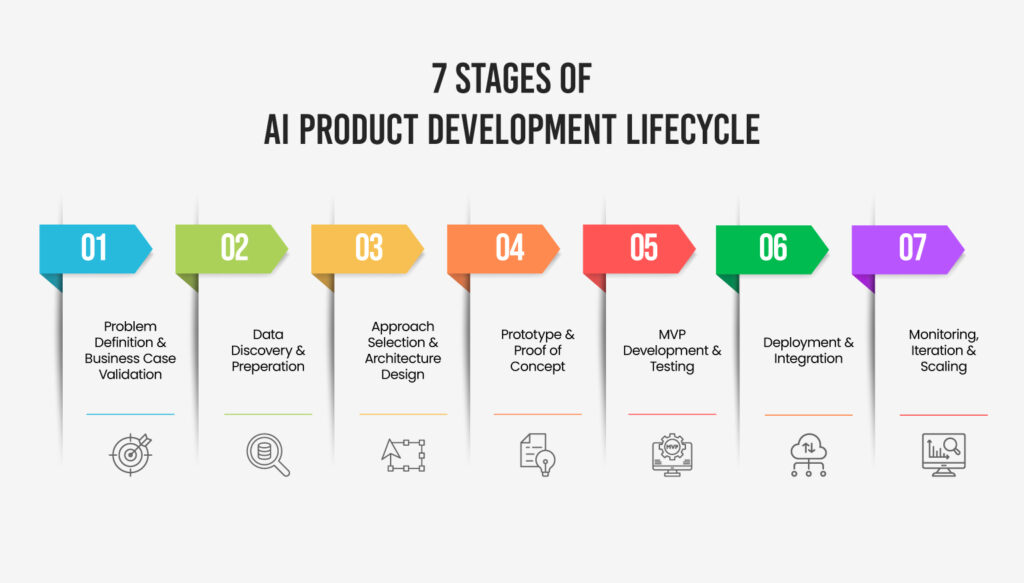
There are seven stages in the AI development lifecycle: problem definition, data discovery, approach selection, prototyping, MVP development, deployment, and ongoing monitoring and iteration.
Each one builds on the last, but the process isn’t strictly linear — insights from later stages routinely send you back to revisit earlier ones, and that’s normal, not a sign you did something wrong.
Think of it less like a straight road and more like a loop with a few detours built in. You’ll move forward through most of it, but don’t be surprised if Stage 5 sends you right back to Stage 2. That’s not failure — that’s just how building something that learns actually works.
Stage 1: Problem Definition & Business Case Validation
Here, the team defines the problem in measurable terms and honestly asks whether AI is even the right tool to solve it. Sometimes it isn’t — and figuring that out now saves everyone months of wasted effort later.
This is the stage that’s most often skipped, usually because everyone’s excited to start building. But “we should use AI for this” isn’t a problem statement — it’s a hunch. A real problem statement looks more like “reduce churn-prediction lag by 30%”, with a number attached and a way to check whether you actually hit it.
A few things typically happen here:
-
- The vague idea gets turned into a specific, testable problem statement
- A success metric gets defined, along with a current baseline to measure against
- Someone does the unglamorous work of asking, “Is AI even necessary, or would a simpler rule-based fix do the job?”
- The team gets honest about what failure would cost, so the investment is justified before any building starts
- The vague idea gets turned into a specific, testable problem statement
Skipping this stage is, by a wide margin, the single biggest reason AI projects fail. It’s tempting to treat it as a formality and rush to the fun part. Resist that. This is essentially the product discovery phase applied specifically to an AI problem statement.
Stage 2: Data Discovery & Preparation
Data discovery and preparation is a systematic audit of what data actually exists, how good it is, and what’s missing before anything meaningful can be built. This is usually the most time-consuming stage in the entire lifecycle, and almost every team underestimates it badly.
Before this stage even starts, it’s worth running an AI readiness assessment to get an honest read on where your data actually stands.
Here’s what this stage generally involves:
-
- Taking stock of every data source available — internal databases, third-party APIs, user-generated content, the works
- Checking that data for quality: is it complete, accurate, and reasonably current?
- Figuring out what needs to be labelled or annotated, and how
- Reviewing privacy laws, consent requirements, and any compliance red flags
- Identifying the gaps — the data you wish you had but don’t, yet
- Taking stock of every data source available — internal databases, third-party APIs, user-generated content, the works
Get this stage wrong, and you won’t find out until much later, usually right when someone asks why the model isn’t performing the way it was supposed to.
Stage 3: Approach Selection & Architecture Design
This is where the team decides how to technically solve the problem — typically choosing between an off-the-shelf API, a retrieval-based setup (RAG), or a fine-tuned custom model. This decision is expensive to walk back later, so it’s worth slowing down and getting it right the first time.
These three options trade off pretty differently:
-
- Off-the-shelf API. It’s the fastest and cheapest to get running but offers the least differentiation since you’re using the same models everyone else has access to.
- RAG (Retrieval-Augmented Generation). The most common choice in 2026 — it blends a general-purpose foundation model with your own proprietary data, retrieved at the moment it’s needed. Choosing between these options is also where the challenges generative AI creates for product owners tend to surface first.
- Fine-tuned model. It costs the most and takes the longest but gives you the most control when the use case demands real domain specificity.
- Off-the-shelf API. It’s the fastest and cheapest to get running but offers the least differentiation since you’re using the same models everyone else has access to.
The right call here isn’t about which option is technically the most impressive — it’s about which one actually matches what Stage 1 said the business needed. A flashy custom model solving a problem that a simple API could’ve handled is a classic way to burn budget for no real gain.
Stage 4: Prototype & Proof of Concept
This exists to answer one question: Does this approach actually work for this problem? It’s deliberately rough around the edges on purpose — the goal here is testing a hypothesis, not building a polished product.
A solid prototype looks like this:
-
- It’s built using real data, not a clean synthetic sample that makes everything look easier than it is
- It gets tested against a small, clearly defined set of examples — not a vague sense of “does this seem okay?”
- It takes a few weeks to put together, not months
- It’s explicitly allowed to fail — and if it does, that’s treated as useful information, not wasted work
- It’s built using real data, not a clean synthetic sample that makes everything look easier than it is
A prototype that doesn’t clear the bar isn’t a setback. It’s a cheap save compared to discovering the same problem after a full MVP has already been built. Or what happens once a prototype clears the bar, scaling an AI proof of concept to production picks up exactly where this stage leaves off
Stage 5: MVP Development & Testing
MVP development and testing build the smallest version of the product that real users can actually use and respond to. That means three pieces working together at the same time: the AI core itself, a usable interface around it, and a way to capture how people actually react to it.
Testing at this stage covers more ground than a typical software MVP would:
-
- Performance testing — does it hit the success metric defined back in Stage 1?
- Edge case and adversarial testing — what happens with weird, unexpected, or deliberately tricky inputs?
- Trust testing — do real users actually believe and act on what the AI is telling them, or do they quietly ignore it?
- Performance testing — does it hit the success metric defined back in Stage 1?
That last point gets overlooked constantly. A model can be statistically accurate and still fail if nobody trusts its output enough to use it.
The single most important investment at this stage is building a way to measure output quality systematically — because if you can’t measure it, you can’t improve it.
Stage 6: Deployment & Integration
This is where the model moves from a working MVP into a real production environment, usually rolled out gradually rather than all at once. Here, the AI products most often get technically stuck, because production requirements are a different beast entirely from prototype requirements.
What needs to be in place here:
-
- A serving layer that can actually handle real traffic without falling over
- Monitoring built specifically for AI output quality — not just whether the servers are up
- Fallback behaviour for when the model returns a low-confidence answer, so it fails gracefully instead of confidently
- Security controls that match how sensitive the underlying data actually is
- A serving layer that can actually handle real traffic without falling over
Stage 7: Monitoring, Iteration & Scaling
This isn’t a final step — it’s a permanent operating mode that starts at launch and runs for as long as the product exists. AI products degrade quietly if nobody’s watching for it, which is exactly why this stage matters just as much as everything that came before it.
This stage generally includes:
-
- Tracking performance and output quality continuously, not just checking in occasionally
- Building retraining pipelines so new data actually feeds back into improving the model
- Capturing user feedback loops — both the explicit kind (ratings, reports) and the implicit kind (did they actually use the output?)
- Planning for cost and latency as usage grows, since both tend to creep up quietly
- Tracking performance and output quality continuously, not just checking in occasionally
Once a product is live, the focus shifts to a product roadmap for post-launch growth rather than the build itself.
Emvigo supports different stages of this lifecycle rather than just one part of it. That can include early discovery and problem framing, AI data readiness, building toward an MVP, and ongoing support once a product is live.
How Is the AI Product Development Lifecycle Different from the Traditional Software Development Lifecycle?
The AI product development process differs from the traditional software development lifecycle in three core ways: it depends on data before development can start, its outcomes aren’t fully predictable, and it doesn’t have a true finish line at launch. These three differences explain most of why AI projects feel harder to plan than typical software work.
In traditional software development, code can be shipped without needing a single real customer record, since the logic behaves the same way every time, regardless of the data flowing through it. For the broader, non-AI version of this process, a complete guide to software product development covers the same comparison from the traditional side.”
The lifecycle of AI product development works differently on both counts: real data is needed before development can properly begin, and because AI systems are probabilistic rather than deterministic, similar inputs can sometimes produce slightly different outputs — which is simply how these systems function, not a flaw to fix.
Conclusion
The real payoff of going through this lifecycle once isn’t just the product you end up with – it’s the judgement your team keeps afterwards. The second AI initiative always moves faster than the first, not because the stages get shorter, but because the team finally has a shared sense of where things tend to go sideways.
That also means the goal was never to follow every stage perfectly. Plenty of strong AI products were built by teams that stumbled somewhere along the way. What separated them was having a structure that made the stumble visible early enough to fix, instead of finding out months later that something had quietly gone wrong.
So if you’re about to start your first AI product, the most useful habit isn’t memorising seven stage names. It’s asking, at every step, “What would tell us if this isn’t working?” — and actually setting up a way to hear the answer.
FAQs
Who should be involved in the AI product development lifecycle, beyond the product manager?
A typical team includes a data or ML engineer, a data scientist or analyst for the data-discovery stages, a designer for the user-facing parts of the MVP, and someone from legal or compliance for data privacy reviews. Not every stage needs every role full-time, but most AI products struggle when one of these is missing entirely rather than just stretched thin.
Does every AI feature need to go through the full seven-stage lifecycle?
Not necessarily at full depth. A small, low-risk feature built on an existing API might move through Stages 1–3 quickly and skip a heavy prototyping phase, while a custom model handling sensitive data warrants slowing down at every stage. The lifecycle scales with risk and complexity — it’s a framework to adapt, not a fixed checklist to complete in full every time.
Is the lifecycle the same for generative AI products as it is for predictive or traditional ML products?
The seven stages stay the same, but the emphasis shifts. Generative AI products tend to spend more time in Stage 3 (choosing between an API, RAG, or fine-tuning) and Stage 5 (trust testing, since outputs are more open-ended), while traditional predictive models often spend more time in Stage 2, since they typically rely on larger structured datasets.
What happens if a team skips the lifecycle and builds straight to production?
It’s not that the product won’t work — sometimes it does, especially for simple use cases. The risk is that problems which would have been caught early (bad data, an unclear success metric, no monitoring plan) surface later instead, usually after real users and real money are already involved, which makes them far more expensive to fix.
How do you know when a product has successfully completed the lifecycle, not just one stage?
There isn’t really a finish line to “complete”, since Stage 7 runs indefinitely. A more useful marker is whether the product has reached a stable operating rhythm — performance is being tracked, retraining happens on a known cadence, and the team isn’t discovering problems through user complaints before the dashboards do.
Does the lifecycle apply if a team is using a third-party AI tool or API instead of building a custom model?
Yes, though some stages get lighter. Data discovery still matters because the tool’s output quality depends on what you feed it, and monitoring still matters because third-party models can change behaviour without notice. What shrinks is mainly Stage 3 and Stage 4, since there’s no architecture decision or custom prototype to build.


